AWS EMR Cost Optimization Guide

May 16, 2024
Guides

AWS EMR (Elastic MapReduce) is Amazon’s managed big data platform which allows clients who need to process gigabytes or petabytes of data to create EC2 instances running the Hadoop File System (HDFS). AWS generally bills storage and compute together inside instances, but AWS EMR allows you to scale them independently, so you can have huge amounts of data without necessarily requiring large amounts of compute. AWS EMR clusters integrate with a wide variety of storage options. The most common and cost-effective are Simple Storage Service (S3) buckets and the HDFS. You can also integrate with dozens of other AWS services, including RDS, S3 Glacier, Redshift, and Data Pipeline.
AWS EMR is powerful, but understanding pricing can be a challenge. Because the service has several unique features and extensively utilizes other AWS services, it’s easy to lose track of all the elements factored into your monthly spend. In this article, I’ll share an overview of AWS EMR’s pricing model, some tips for controlling your AWS EMR costs, and resources for monitoring your EMR spend. While it’s hard to generalize advice for EMR because each data warehouse is different, this article should give you a starting point for understanding how your use case will be priced by Amazon.
Looking for additional practical and helpful articles to reduce your AWS cost?
Check out these other articles that we wrote up:
- AWS RDS Pricing and Optimization
- AWS S3 Pricing and Optimization Guide
- Reduce Your AWS Data Transfer Costs Guide
AWS EMR Cluster Pricing
Most of the costs of running an AWS EMR cluster come from the utilization of other AWS resources, like EC2 instances and S3 storage. To run a job, an AWS EMR cluster must have at least one primary node and one core node. The EC2 instances in the cluster are charged by the minute based on instance size. Every instance in a cluster is created with an attached, ephemeral EBS volume with 10 GiB of provisioned space (instances without attached instance storage are given more) to hold HDFS data and any temporary data like caching or buffers. These volumes are charged per GiB provisioned and prorated over the time the instance runs.
The data to process and data processing application are stored in S3 buckets, where you’re charged per Gibibyte (GiB) per month. A job is submitted to the EMR cluster via steps or a Hadoop job. You can also automate cluster launch using a service like Step Functions, Data Pipeline, or Lambda Functions. To start the job, the EMR File System (EMRFS) retrieves data from S3 (adding GET request fees to the S3 bucket). Any buckets in a different region will also be charged per GiB for data transferred to the cluster.
You can set the minimum and maximum number of EC2 instances your EMR cluster uses to help control your costs vs. availability. For example, this cluster uses managed scaling, and has the maximum number of non-primary nodes set to “3”:
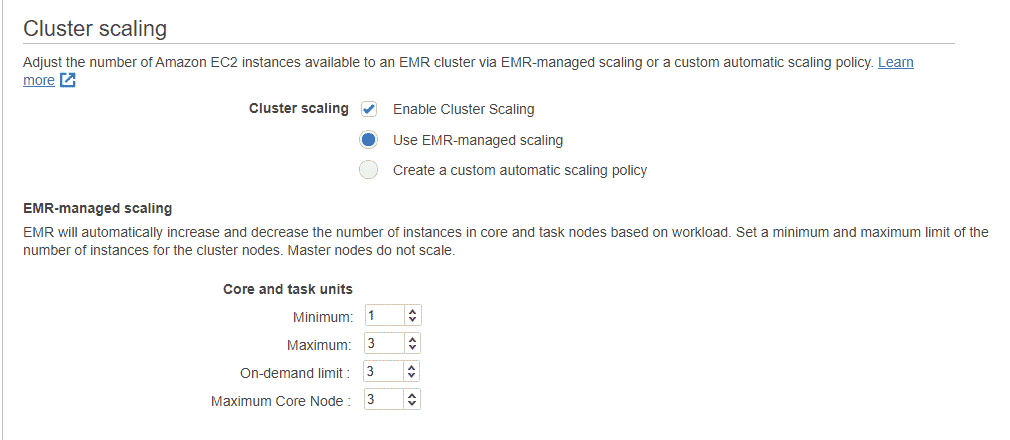
Once the job starts, EMR will monitor utilization and add nodes if needed. EMR managed scaling adds nodes in a specific order: On-Demand core nodes, On-Demand task nodes, Spot instance core nodes, and Spot instance task nodes. These additional instances also have costs and attached EBS volumes.
Other data, like configurations for auto-scaling instances and log data can also be stored in S3 buckets. Once the job completes (or finishes a step), intermediate data can be stored in HDFS for more processing or written to an S3 bucket (with a PUT request fee, storage costs, and any cross regions data-transfer charges). At the end of the job, EMR will terminate idle instances (and attached EBS volumes) down to the minimum, while remaining instances wait for the next workload.
In short, if your EMR cluster is sitting idly, waiting for data, it should scale down appropriately, but you’ll still pay for storage costs during downtime. While putting a cap on the number of EC2 instances EMR uses helps you control your costs, your data warehouse might struggle if it’s hit with a sudden spike.
AWS EMR Cost Optimization Tips
Now that we’ve laid the groundwork for how pricing in EMR works, let’s look at some of the levers you can pull to decrease your EMR costs.
1. Prepare Your Data
When you’re working on the petabyte scale, disorganized data can dramatically increase costs by increasing the amount of time it takes to find the data you intend to process. Good ways to improve the efficiency of your EMR cluster are data partitioning, compression, and formatting.
Data partitioning is vital to ensure you’re not wading through an entire data lake to find the few lines of data you want to process, racking up bandwidth and compute costs in the process. You can partition data by carefully planning to use prefixes and S3 Select. Or use a Hadoop tool like Hive, Presto, or Spark in tandem with a metadata storage service like Glue.
Partitioning by date is common and suits many tasks, but you can partition by any key. A daily partition could prevent an EMR cluster from requesting and scanning a week’s worth of data. Much like database indexing, some partitioning is extremely useful, but over-partitioning can hurt performance by forcing the primary node to track additional metadata and distribute many small files. When reading data, aim to keep partitions larger than 128 MB (the default HDFS block size) to avoid the performance hit associated with loading many small files.
Data compression has the obvious benefit of reducing storage space. It also saves on bandwidth for data passed in and out of your cluster. Hadoop can handle reading gzip, bzip2, LZO, and snappy compressed files without any additional configuration. Gzip is not splittable after compression, so it’s not as appealing as other compression formats. You can also configure EMR to compress the output of your job, saving bandwidth and storage in both directions.
Data formatting is another place to make gains. When dealing with huge amounts of data, finding the data you need can take up a significant amount of your compute time. Apache Parquet and Apache ORC are columnar data formats optimized for analytics that pre-aggregate metadata about columns. If your EMR queries column intensive data like sum, max, or count, you can see significant speed improvements by reformatting data like CSVs into one of these columnar formats.
2. Use the Right Instance Type
Once your data is stored efficiently, you can bring attention to optimizing how that data is processed. The EC2 instances EMR uses to process data and run the cluster are charged per second. The cost of EC2 instances scales with size, so doubling the size of an instance doubles the hourly cost, but the cost of managing the EMR overhead for a cluster sometimes remains fixed. For many instance families, the hourly EMR fee for an .8xlarge is the same as the hourly EMR fee for a .24xlarge machine. This means larger machines running many tasks are more cost efficient, they decrease the percentage of your budget spent supporting EMR overhead.
3. Choose Your AWS EC2 Pricing
There are four options for purchasing EC2 instances:
- On-Demand instances can be started or shut down at any time with no commitment and are the most expensive. The upside is that they’ll always be available and can’t be taken away (like spot instances can).
- One and three year reserved instances are On-Demand EC2 instances you reserve in exchange for discounts of 40% to 70%, but you’re committing to a long-term commitment with a specific instance family within a specific region .
- Savings Plans are a slightly more flexible version of reserved instances. You still commit to purchase a certain amount of computer for a one or three year term, but you can choose to change instance family and region. This contract for compute can also be applied to AWS Fargate and AWS Lambda usage.
- Spot instances allow clients to purchase unused EC2 capacity, with discounts that can reach 90% and are tied to demand over time. The downside is that spot instances could be claimed back at any time, so they aren’t appropriate for most long-running jobs.
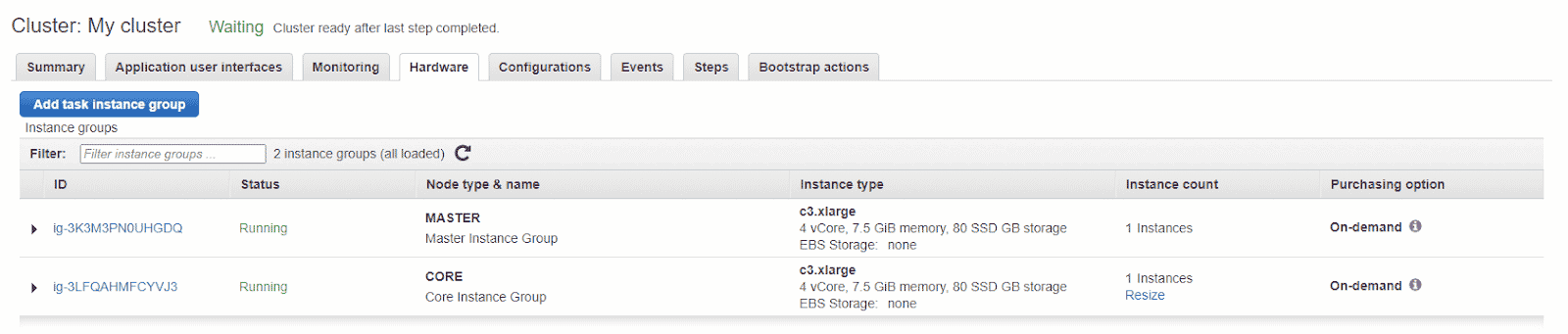
The best way to determine which instance type to use is by testing your application in EMR while monitoring your cluster through the EMR management console, log files, and CloudWatch metrics. You want to be fully utilizing as much of your EMR system as possible, making sure you don’t have large amounts of compute idling while ensuring you can reliably hit your SLAs.
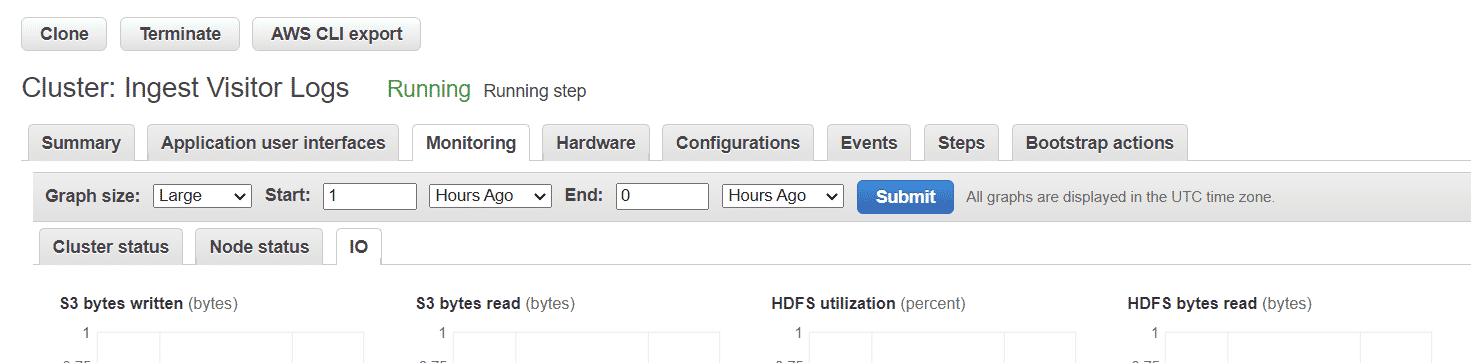
4. Use the Right Number of Primary, Core, and Task Nodes
There are three types of nodes in an EMR cluster. It’s important to understand what they do so you can devote the right number of instances to each of these types.
The primary node (there can only be one or three running) manages the cluster and tracks the health of nodes by running the YARN Resource Manager and the HDFS Name Node Service. These machines don’t run tasks and can be smaller than other nodes (the exception is if your cluster runs multiple steps in parallel). Having three primary nodes gives you redundancy in case one goes down, but you will obviously pay three times as much for the peace of mind.
Core nodes run tasks and speak to HDFS by running the HDFS DataNode Daemon and the YARN Node Manager service. These are the workhorses of any EMR cluster and can be scaled up or down as needed.
Task nodes don’t know about HDFS and only run the YARN Node Manager service. They are best suited for parallel computation, like Hadoop MapReduce tasks and Spark executors. Because they can be reclaimed without risking losing data stored in HDFS, they are ideal candidates to become Spot instances.
While EMR handles the scaling up and down of core and task nodes, you have the ability to set minimums and maximums. If your maximum is too low, large jobs might back up and take a long time to run. If your minimum is too low, spikes in data take longer as more instances ramp up. On the flip side, if your maximum is too high, an error in your data pipeline could lead to huge cost increases.
5. Instance Configuration
Once you’ve tested and selected the appropriate instance types, sizes, and number of nodes, you have to make a configuration decision. You can deploy an instance fleet or uniform instance groups.
Instance fleets are flexible and designed to utilize Spot instances effectively. When creating an instance fleet, you specify up to five instance types, a range of availability zones (avoid saving a few cents on instances only to spend them transferring data between zones), a target for Spot and On-Demand instances, and a maximum price you’d pay for a Spot instance. When the fleet launches, EMR provisions instances until your targets are met.
You can set a provisioning timeout, which allows you to terminate the cluster or switch to On-Demand instances if no Spot instances are available. Instance fleets also support Spot instances for predefined durations, allowing your cluster to confidently access a Spot instance for 1 to 6 hours.
Running all your EMR clusters as Spot Instances would be great for your budget but will leave you a system you can’t always use to process work promptly. Evaluate your requirements, plan to have more expensive and more reliable long-running instances to ensure you meet your SLAs while adding cheaper, less reliable Spot instances to handle spikes in demand.
Uniform Instance Groups are more targeted, requiring you to specify a single instance size and decide between On Demand on Spot instances before launching. Instance Groups are perfect for tasks that are well understood and need a concrete, consistent amount of resources. Instance Fleets are great for grabbing Spot instances where possible while allowing the cluster to fall back to On-Demand instances if needed.
6. Scaling AWS EMR Clusters
AWS EMR clusters are big, powerful, and expensive. EMR utilization also often comes in peaks and valleys of utilization, making scaling your cluster a good cost-saving option when handling usage spikes. Instance fleets and uniform instance clusters can both use EMR Managed Scaling.
This scaling service automatically adds nodes when utilization is high and removes them when it decreases. Unfortunately, it’s only available for applications that use Yet Another Resource Manager (YARN) (sorry, Presto). If you’re running an instance group, you can also specify your own scaling policy using a CloudWatch metric and other parameters you specify. This can give you more fine-grained control over scaling, but it’s obviously more complicated to set up.
7. Terminate AWS EMR clusters
Another fundamental decision you’ll have to make about every EMR cluster you spin up is whether it should terminate after running the job or keep running?
Terminating clusters after running jobs is great for saving money – you no longer pay for an instance or its attached storage – but auto-terminating clusters also has drawbacks. Any data in the HDFS is lost forever upon cluster termination, so you will have to write stateless jobs that rely on a metadata store in S3 or Glue.
Auto-termination is also inefficient when running many small jobs. It generally takes less than 15 minutes for a cluster to get provisioned and start processing data, but if a job takes 5 minutes to run and you’re running 10 in a row, auto-termination quickly takes a toll.
To get the most out of long-running clusters, try to smooth out utilization over time. Scatter jobs throughout the day, and try to draw all the EMR users in your organization to the instance to fill gaps in long-running clusters. Long-running, large clusters can be quite cost-effective. Instance costs decrease relative to size, and the EMR fees on top often don’t increase when increasing instance size, increasing the relative value.
Monitoring AWS EMR Costs
Now that your AWS EMR cluster has instances scaling smoothly while reading beautifully compressed and formatted data, check Cost Explorer to track your cost reduction progress.
Cost Explorer gives you a helpful map of what’s running in your organization but requires some attention to yield the greatest gains. Tag your resources, giving each cluster an owner and business unit to attribute your costs to. Tagging is especially important for EMR because it relies on so many other Amazon services. It can be really hard to differentiate between the many resources used by your EMR cluster when they’re in the same AWS account as your production application.
Other AWS EMR Resource
If you’re looking for more practical articles on this subject, another solid resource can be found on Teads engineering blog. This article was written by Wassim Almaaoui and he describes 3 measures that helped them significantly lower their data processing cost on EMR:
- Run Workloads on Spot Instances
- Leverage the EMR pricing of bigger EC2 Instances.
- Automatically detect idle clusters (and terminate them ASAP).
Check this article out when you get a chance to supplement this one: Reducing AWS EMR data processing costs
Knowing Your Requirements, Meeting Your Goals
In this post, you’ve learned how EMR pricing works and what you can do to minimize and track your EMR costs. It’s possible to grow your EMR infrastructure while controlling costs, but it will likely take a deep understanding of your data processing requirements and a little trial and error. EMR can eat up huge amounts of storage, so be sure you partition, compress, and format data to reduce your storage costs. Categorize jobs according to priority, schedule, and resource requirements, then nestle them into the right instance types. Consider cluster termination for jobs that run only occasionally and auto-scale long-running instances when appropriate.
If this is overwhelming, CloudForecast can help. Reach out to our CTO, Francois ([email protected]), if you’d like help implementing a long-term cost-reduction strategy for EMR.
John Gramila
John is a freelance software engineer based in Chicago who writes about hosting and cloud computing topics.
Blog
More from CloudForecast




Cloud Cost Management is Easy With CloudForecast
We would love to learn more about the problems you are facing around AWS and Azure cost. Connect with us directly and we’ll schedule a time to chat!
Start Free Trial