Amazon S3 Pricing Guide (2026): Storage Classes, Requests & Hidden Costs

February 23, 2026
Guides

In today’s cloud-driven world, organizations of all sizes rely heavily on Amazon S3 to store, manage, and access ever-growing volumes of data. S3 is one of AWS’s most reliable and widely-used services — but it’s also one of the easiest to overspend on. That’s largely due to its complicated and confusing pricing structure. If you’ve ever stared at the S3 pricing page and thought, “So how much is this actually going to cost me?” — you’re not alone.
In this guide, we’ll break down Amazon S3 pricing into three simple pillars: storage classes, requests, and data transfer. We’ll cover all eight AWS S3 storage classes including the newest additions, walk through current pricing tables, and share practical tips to help you cut costs. By the end, you’ll have everything you need to navigate S3 pricing with confidence — and hopefully, save some serious money along the way.
Looking For Other AWS Cost Guides?
- Data Transfer Costs and Optimization Guide
- CloudFront Pricing and Cost Optimization Guide
- DynamoDB Pricing and Cost Optimization Guide
- ECS Pricing and Container Optimization Guide
- EMR Cost Optimization Guide
- NAT Gateway Pricing and Cost Reduction Guide
- RDS Pricing and Cost Optimization Guide
- Tagging Best Practices and Strategies
- ZeroWaste Report Interactive Demo
What is Amazon S3?
You likely already know what S3 is, but a quick refresher: Amazon Simple Storage Service (S3) is AWS’s cloud storage solution. It’s a reliable infrastructure for organizations to store and retrieve vast amounts of data: think documents, spreadsheets, images, videos, and more.
When it comes to pricing, yes, there’s a bunch of information on the S3 pricing page. But we can greatly simplify it by classifying costs based on these three main pillars:
- Storage: This is the amount of data you’re storing in S3, but also the storage class you’re using on that data. S3 storage classes, such as Standard, Intelligent-Tiering, and Glacier, each have their own cost structure. As we’ll see shortly, storage classes greatly influence that final number on your monthly AWS bill!
- Requests: These are the API calls that you make involving your data in S3: uploading, downloading, copying files, listing objects, or deleting them. Pricing depends on the type and frequency of requests.
- Data Transfers: This third and final pillar is all about moving data to and from S3. While data transfers into S3 are free, AWS bills data transfers out of S3 based on volume and transfer type (cross-region or cross-AZ). There are ways to be cost-efficient with your data transfers, and we’ll explore those in a later section as well.
If you ever get dizzy looking at the S3 pricing page, just remember that all costs essentially fit under one of these three pillars. Let’s now dive deeper into each pillar.
How Amazon S3 Pricing and S3 Storage Classes Work
The biggest thing you can do to understand S3 pricing is to become familiar with the different storage classes. S3 storage classes represent different tiers or levels of durability, availability, performance, and cost. Each one is designed to accommodate specific use cases and workload requirements. By using the appropriate storage class for your data, you can maximize efficiency and reduce costs.
Related to S3 storage classes are lifecycle policies. The s3 lifecycle policy enables you to automate the transition of objects between different storage classes based on predefined rules. With the right lifecycle policies in place, you can seamlessly move data between storage classes as it changes in access frequency.
We’ll see lifecycle policies in action really soon. For now, let’s explore the eight S3 storage classes available. In general, performance and availability is the best for S3 Standard, and tapers off as you go down the list in exchange for lower costs.
- Amazon S3 Standard: The default storage class offering high durability, availability, and low latency.
- Amazon S3 Express One Zone: AWS’s highest-performance S3 storage class, designed for latency-sensitive workloads that need consistent single-digit millisecond access. Data is stored in a single Availability Zone.
- Amazon S3 Intelligent-Tiering: Automatically optimizes costs by moving objects between three access tiers based on usage patterns.
- Amazon S3 Infrequent Access (IA): Designed for infrequently accessed data.
- Amazon S3 One Zone – Infrequent Access: Similar to Amazon S3 Infrequent Access, but data is stored in just one Availability Zone (AZ), further reducing costs.
- Amazon S3 Glacier Instant Retrieval: Optimized for long-term archival storage where you still need near real-time access.
- Amazon S3 Glacier Flexible Retrieval: Optimized for long-term archival storage where retrieving data in minutes is not necessary.
- Amazon S3 Glacier Deep Archive: The most cost-effective storage class for long-term archival. Retrieval can take hours.
Amazon S3 Standard Storage
Amazon S3 Standard Storage is the flagship and most widely used storage class. Its durability, performance, and low-latency characteristics make it suitable for frequently accessed data and applications that require immediate access.
Amazon S3 Standard pricing is very straightforward: $0.023 per GB/month, which tapers off slightly as your usage increases past 50 TB. While Amazon S3 is priced higher than all other S3 storage classes, it offers the highest level of availability and low-latency performance.
Amazon S3 Express One Zone
AWS’s highest-performance S3 storage class, purpose-built for workloads requiring consistent single-digit millisecond data access. It stores data in a single Availability Zone and uses a separate bucket type called a directory bucket, rather than the general purpose buckets used by every other storage class. It’s significantly faster and cheaper on requests than S3 Standard, but not suitable for data that needs multi-AZ redundancy.
Amazon S3 Intelligent-Tiering
Amazon S3 Intelligent-Tiering is a unique offering that automatically optimizes storage costs by moving data between three tiers based on usage patterns. Under the hood, it uses machine learning algorithms to analyze your access patterns over time and determine a strategy to help you save the most money without sacrificing performance.
If you use Intelligent-Tiering, you’re billed a flat rate of $0.0025 per 1,000 objects above 128 KB in size. Then, it’s a pay-as-you-go model for storage in each of the three tiers: Frequent Access, Infrequent Access, and Archive Instant Access.
Amazon S3 Infrequent Access
As its name suggests, Amazon S3 Infrequent Access is designed for storing infrequently accessed data. You might stick long-lived backups, secondary replicas, and disaster recovery data into S3 Infrequent Access.
S3 Infrequent Access costs $0.0125 per GB/month. While S3 Infrequent Access is cheaper than S3 Standard, there is a high retrieval fee when accessing data in this tier.
Amazon S3 One Zone – Infrequent Access
Amazon S3 One Zone – Infrequent Access is similar to Amazon S3 Infrequent Access, but all data is stored in a single AZ. This is ideal for data that doesn’t have to be replicated across regions.
S3 One Zone – Infrequent Access costs $0.01 per GB/month. While it is cheaper than S3 Infrequent Access, putting all your data in one AZ makes it less resilient to failures. Be sure to evaluate the impact of potential AZ outages before opting into this class.
Amazon S3 Glacier Instant Retrieval
Amazon S3 Glacier Instant Retrieval is designed for scenarios where quick access to archived data is crucial (within minutes). This is the fastest retrieval time compared to other Glacier storage classes, but it also comes with a higher cost per retrieval. Glacier Instant Retrieval is good for use-cases such as data analytics or media processing.
For pricing, Glacier Instant Retrieval costs $0.004 per GB/month.
Amazon S3 Glacier Flexible Retrieval
Amazon S3 Glacier Flexible Retrieval is designed for cost-effective archival storage of data that is accessed infrequently. It strikes a balance between cost savings and data retrieval times, making it an ideal choice for long-term data storage with occasional or on-demand access requirements.
Glacier Flexible Retrieval costs $0.0036 per GB/month.
Amazon S3 Glacier Deep Archive
Amazon S3 Glacier Deep Archive is the most cost-effective option within the Glacier family of storage classes. However, you only want to put data that is rarely accessed here, since data retrieval typically takes hours. It’s a good option for preserving data stored for regulatory compliance purposes.
Glacier Deep Archive costs $0.00099 per GB/month.
Summary of S3 Storage Classes and Pricing
Here’s a handy table that summarizes the 7 s3 storage classes, their key features, and s3 pricing:
| Storage Class | Use Cases & Considerations | Pricing (US East, N. Virginia) |
| Amazon S3 Express One Zone | High-frequency, latency-sensitive workloads: ML training, real-time analytics. Single-AZ only — not for data requiring multi-AZ redundancy. | $0.16 per GB/month $0.0025 per 1,000 PUT/COPY/POST/LIST requests $0.0002 per 1,000 GET requests |
| Amazon S3 Standard Storage | Suitable for objects that require frequent data access:Application dataConfiguration filesWebsite content | $0.023 per GB/month (first 50TB)$0.022 per GB/month (next 450TB)$0.021 per GB/month (over 500TB) |
| Amazon S3 Intelligent-Tiering | Suitable for use cases where you may have to get objects with an unpredictable access pattern:Backup dataDisaster recovery | $0.0025 per 1,000 objects above 128 KB$0.023 per GB/month (Frequent Access Tier, first 50 TB)$0.0125 per GB/month (Infrequent Access Tier)$0.004 per GB/month (Archive Instant Access Tier) |
| Amazon S3 Infrequent Access | Suitable for objects that you access infrequently:Historical log dataBackup of non-mission-critical business information | $0.0125 per GB/month |
| Amazon S3 One Zone – Infrequent Access | Suitable for objects that you access infrequently, and don’t have cross-region replication requirements. Stored data is lost permanently if a destructive event occurs in the AZ. | $0.01 per GB/month |
| Amazon S3 Glacier Instant Retrieval | Suitable for archived long-term data that may still require rapid access:Business intelligence dataMedia processing | $0.004 per GB/month |
| Amazon S3 Glacier Flexible Retrieval | Suitable for archived long-term data that doesn’t require rapid access:Long-term data archivesRecord retention for compliance | $0.0036 per GB/month |
| Amazon S3 Glacier Deep Archive | Suitable for archived long-term data that you shouldn’t need to access:Record retention for compliance | $0.00099 per GB/month |
Amazon S3 Requests & Data Retrieval
The second major cost pillar is requests: the main ones include PUT, COPY, POST, LIST, GET, and SELECT requests. This pillar also encompasses requests to transition into different storage classes, as well as data retrieval requests for Glacier storage classes.
Summary of S3 Request & Data Retrieval Pricing
Here’s a condensed table summarizing S3 Request & Data Retrieval pricing (for US East, N. Virginia):
| Category | Pricing |
| PUT, COPY, POST, or LIST requests | $0.005 (per 1,000 requests) |
| GET, SELECT, and other requests | $0.0004 (per 1,000 requests) |
| Lifecycle Transition requests into… | All prices are per 1,000 requests:$0.01 (S3 Intelligent Tiering, Infrequent Access, One Zone Infrequent Access)$0.02 (S3 Glacier Instant Retrieval)$0.03 (S3 Glacier Flexible Retrieval)$0.05 (S3 Glacier Deep Archive) |
| Data Retrieval requests | All prices are per 1,000 requests:$10.00 (Archive Access/Glacier Flexible, Expedited)$0.05 (S3 Glacier Flexible, Standard)$0.10 (S3 Glacier Deep Archive, Standard) |
Amazon S3 Data Transfers
And finally, we have the third pillar: data transfers. Data transfer pricing in AWS is notoriously confusing. Luckily, most services share a similar pricing model when it comes to AWS, and S3 is no exception to that. Here are some general rules to know about AWS data transfer pricing:
- In general, data transfers in (DTI) to AWS from the Internet are free.
- In general, data transfers out (DTO) of AWS to the Internet are not free, though there are a few nuances:
- The first 100GB per month of DTO is free, aggregated across all AWS services and regions (except China and GovCloud) — not just S3
- Data transferred between S3 buckets in the same AWS region is free;
- Data transferred from an S3 bucket to any AWS service in the same AWS Region as the S3 bucket (including to a different account in the same AWS region) is free;
- Data transferred out to Amazon CloudFront is free.
The key to the DTO conditions is to note the start and destination regions of your data. In general, if you’re going cross-region, be prepared to pay for data transfers.
Summary of S3 Data Transfer Pricing
One last handy table summarizing our third pillar (again, costs based on US East, N. Virginia):
| Category | Pricing |
| DTI from Internet | $0.00 per GB |
| DTO to Internet | $0.09 per GB (first 10 TB/month)$0.085 per GB (next 40 TB/month)$0.07 per GB (next 100 TB/month)$0.05 per GB (greater than 150 TB/month) |
| DTO from Amazon S3 to… | Depends on the destination Region, for example:$0.00 per GB, CloudFront$0.01 per GB, US East (Ohio)$0.02 per GB, Europe (London)$0.02 per GB, Asia Pacific (Tokyo) |
S3 Cost Optimization: Understanding Your S3 Access Patterns
Now that we’re familiar with the 3 cost pillars of S3, let’s run through an exercise to do some cost optimization. We’ll focus mainly on the first pillar, storage classes.
By default, your objects are put into the Standard tier. However, we now know you can optimize your costs by moving your objects into different S3 classes where appropriate.
In this section, you’ll learn how to use Amazon S3 Storage Class Analysis to determine which Standard tier files can be moved to a less frequent access tier. This will help you decide whether it’s worth investing in a S3 lifecycle policy, and how much you might save by using one. It could also be used to tag your objects in S3 and move them to the right tier.
Running AWS S3 Storage Class Analysis
To kick off the analysis, navigate to the S3 console and choose one of your buckets. Then, choose the Metrics tab and scroll down until you see the Storage Class Analysis section:
From here, click the Create analytics configuration button. On the next screen, you have a couple configuration options:
- Name: Give a name to your configuration.
- Configuration scope: The settings here allow you to choose whether you want to analyze the whole bucket, or just a subset of files using filters.
- Export CSV: Decide whether to export the results or not.
Analyzing the Results
After you create the configuration, AWS will start the storage classes analysis. Depending on the size of your bucket, you might be able to see results fairly quickly. Here’s a sample of what you might see:
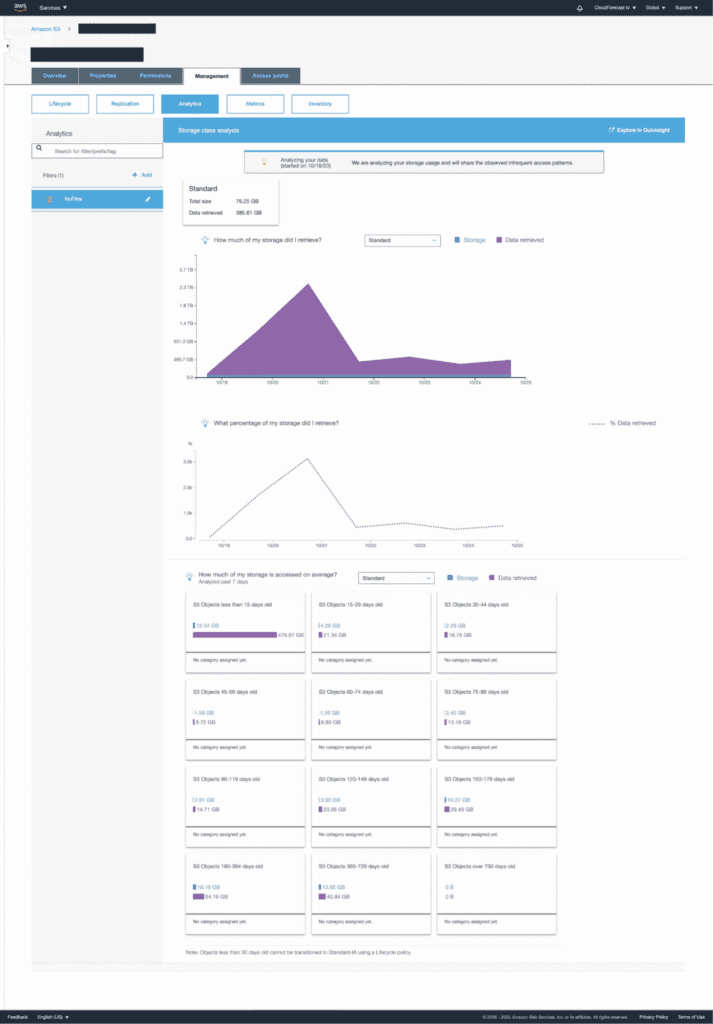
The chart and summary boxes show you the total size of the objects in S3 that you’re storing versus the amount that’s been retrieved. We really want to focus on data points in the summary boxes here. For instance, you’ll notice that 13.92 GB worth of the oldest files in the bucket (365 – 729 days old) are still being retrieved regularly–40.84 GB worth in the past seven days. This suggests that we might want to keep all of these files in S3 Standard.
On the other hand, the analytics in the following image show a very different usage pattern:
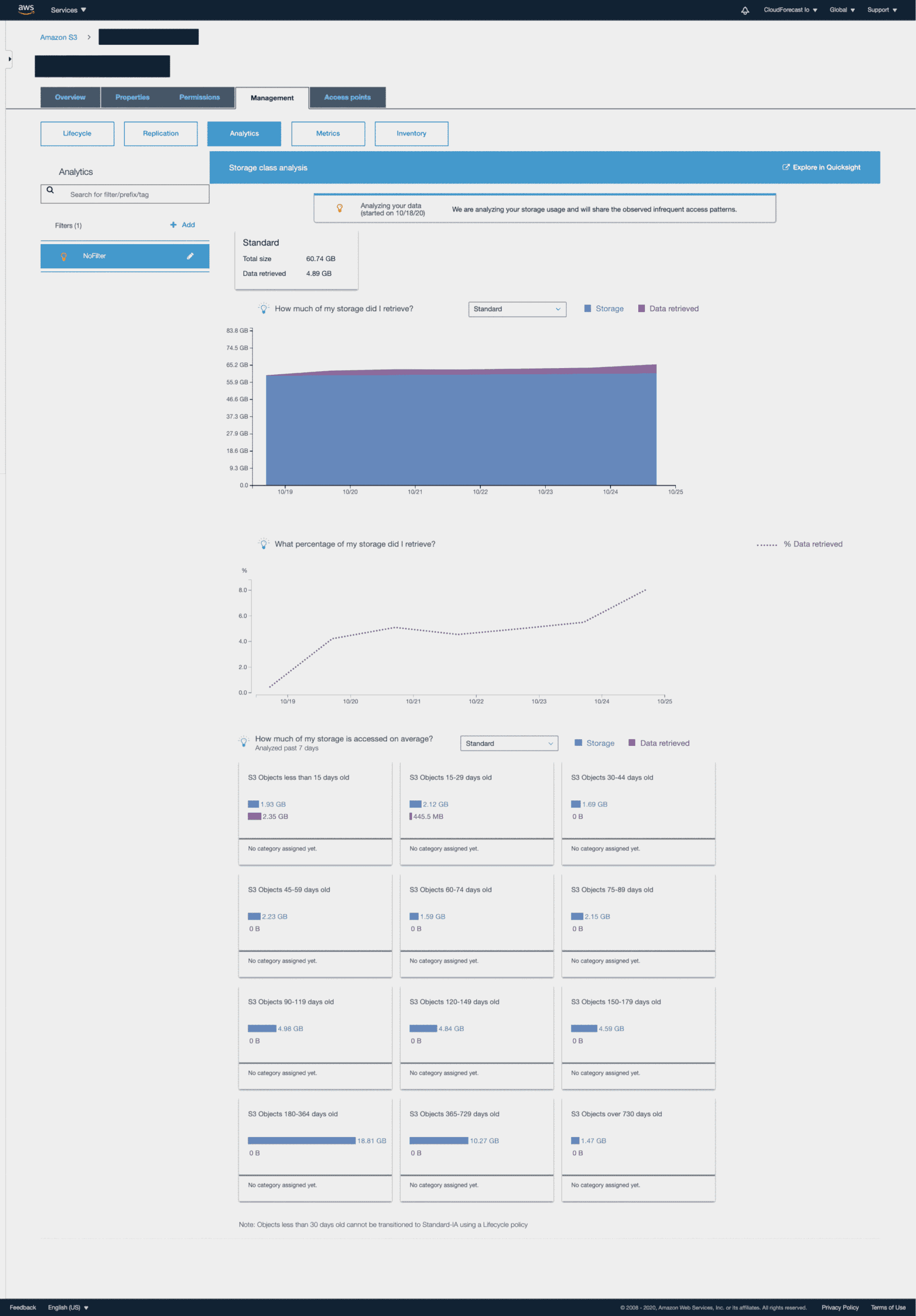
In this bucket, none of the files over 30 days old have been accessed at all in the past seven days! This might indicate that you can move some of these older files to the Infrequent Access tier or even Glacier. But do be careful–moving files in and out of these longer-term storage patterns does incur a cost, as we saw in the Requests pillar.
Once AWS has had a go at your bucket for a while, AWS will offer some recommendations. Here’s an example of what you might see:
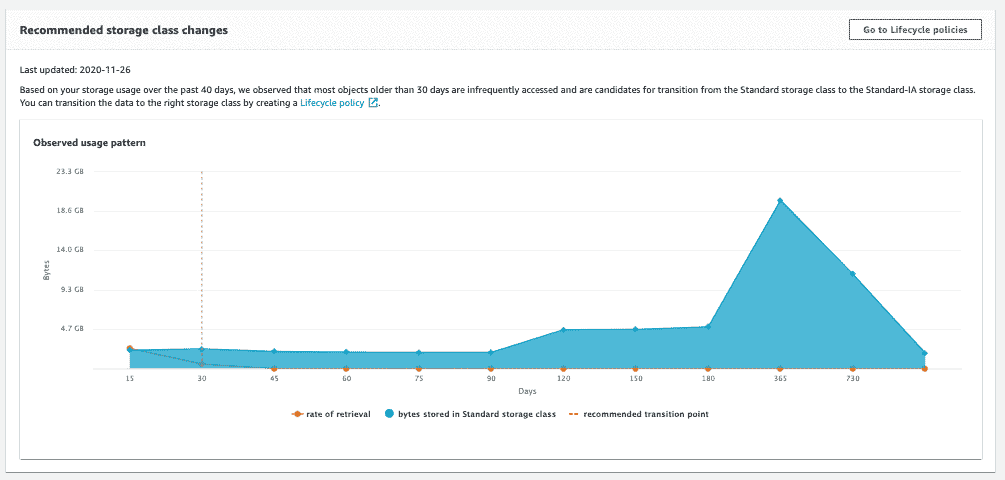
To read this graph, focus on the orange “rate of retrieval” line. It drops to almost zero after a file is 30 days old (the x-axis). The large area of blue in the right hand side of the graph indicates that there is a lot of storage being consumed by older, infrequently accessed files in this bucket. Definitely a sign to move files into a different storage class!
So how do you actually put this analysis to good use? That’s where lifecycle rules come in.
S3 Cost Optimization: Creating an S3 Lifecycle Rule
When you create a lifecycle rule, you’re telling S3 to move files to another storage tier, or delete files automatically based on their age. You can use tags or file prefixes to filter which files you want a certain lifecycle rule to apply to. You can also have a lifecycle rule apply to an entire bucket.
To get started, navigate to the S3 console and choose one of your buckets. Then, choose the Management tab. The first section should show Lifecycle rules; choose Create lifecycle rule.

Let’s assume we have a bucket similar to our second example above, where no files older than thirty days are being accessed. You might create a lifecycle rule that:
- Moves files to the Infrequent Access (Standard-IA) tier after they’re 45 days old. This gives you some margin of error, but you could also choose 30 days if you like.
- Moves files to Glacier after they’re 365 days old.
- Expires files after they’re ten years old.
In the console, your access rule setup would look like this:
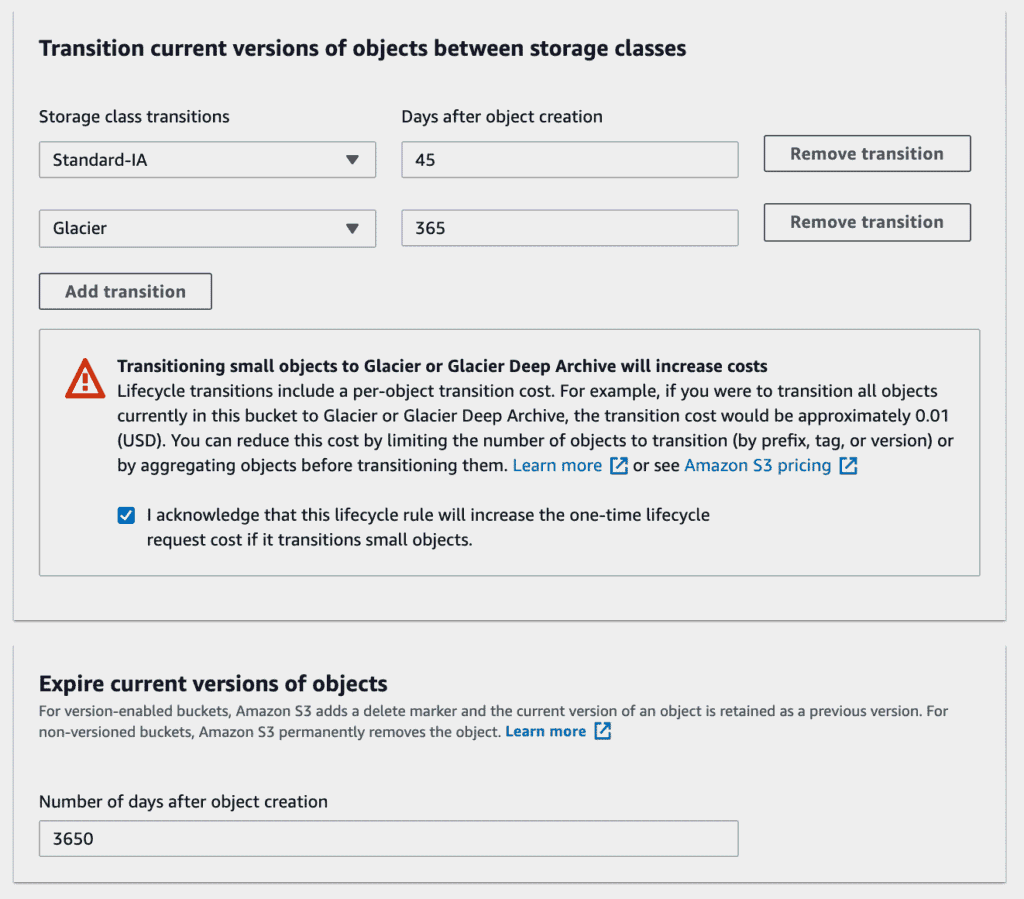
A final word of caution: be careful when setting up lifecycle policies. Moving files in and out of different storage classes — particularly Glacier — can get very expensive if misconfigured. Small mistakes in your lifecycle policy could potentially add thousands to your AWS bill!
One way to catch these issues before they compound is to use CloudForecast’s ZeroWaste report, which automatically flags S3 buckets without lifecycle policies and surfaces idle or over-provisioned storage across your AWS account. You can also sign up for CloudForecast’s daily AWS spending alerts to monitor for cost spikes in real time — so you’re never caught off guard by an unexpected line item on your bill.
Additional S3 Cost Optimization Tips
Configuring your storage classes right is the quickest way to saving on storage costs. Here are some additional miscellaneous “quick wins” that you might implement to immediately start saving more on S3.
Use Cost and Usage Reports
The most comprehensive resource that AWS offers for understanding your costs is the Cost and Usage Report (CUR). We have an entire article dedicated to this topic: check out What is the AWS Cost and Usage Report? for more info.
Effective S3 Bucket Organization
Since lifecycle policies can use file prefixes or tags as filters, consider implementing an organization system for your S3 buckets. Common tagging strategies might include:
- Prefixing file names with an expiration date
- Tagging objects with the responsible team’s name
- Tagging data with each customer’s company or organization name
Having a consistent system for organizing objects in S3 will ensure that you can write effective lifecycle policies. It can also help prevent you from deleting important files.
Don’t Forget Your Logs
If you’re storing your CloudWatch logs in Amazon S3, one of the easiest ways to decrease your S3 costs is to expire old log files automatically. As we’ve seen, you can do this via a lifecycle policy. But be careful: many regulations require organizations to retain logs for months or years.
What Does S3 Overspend Actually Look Like?
It’s one thing to know the pricing — it’s another to know where teams actually lose money. Based on what we see across CloudForecast customers managing significant AWS spend, S3 typically accounts for 8–20% of total AWS costs. But a disproportionate share of that is avoidable.
The most common culprits we see? Buckets with no lifecycle policy that have been quietly accumulating years of Standard-tier objects that were never transitioned. Versioning enabled without expiration rules, causing object counts to balloon silently month over month. And Glacier Expedited retrievals triggered by engineers who didn’t realize the cost difference versus Standard retrieval — a mistake that can turn a $0.05 request into a $10.00 one.
The single fastest win: run the S3 Storage Class Analysis tool on your five largest buckets and implement lifecycle rules in the same week. Most teams discover that 20–40% of their S3 storage can be moved to a cheaper class immediately, with no impact on application performance. That’s real money back in your budget with a few hours of work.
Conclusion
Storage. Requests. Data transfers. These are the 3 main pillars of cost in S3. Though it can be difficult to understand S3 pricing, looking at it from this perspective makes it all easier to digest.
In this article, you took an in-depth look into all three of these cost factors. We summarized how AWS prices each one–if you ever forget some of the details, refer to the handy summary tables we presented throughout this article.
Now that you know how to run the storage class analysis tool to understand your S3 usage, why not give it a try yourself? Then, you can create lifecycle policies that properly transfer your S3 files to the appropriate storage class. If you’d like additional help understanding your AWS spending, consider giving CloudForecast a try.
Alexander Yu
Alexander Yu is a technical writer at AWS by day and a freelance writer by night. After completing his BS in electrical engineering and computer science from UC Berkeley, he became a software developer at AWS for almost three years before transitioning into technical writing. He lives in Seattle with his dog Yuna.
Blog
More from CloudForecast




Cloud Cost Management is Easy With CloudForecast
We would love to learn more about the problems you are facing around AWS and Azure cost. Connect with us directly and we’ll schedule a time to chat!
Start Free Trial